StackHawk makes the best dynamic application security test (DAST) scanner on the market today. In order to tap its full potential, you need to run it frequently as an integral part of your continuous delivery process. That way, you can stay on top of new security bugs while they are a small matter, and before they ever reach production.
But what does it mean to run StackHawk in continuous delivery? What does continuous delivery even mean? Where does StackHawk fit in? Won’t it slow down our delivery process? Couldn’t we just schedule it? What if our app is a giant monolith? What if we run microservices in Kubernetes? The purpose of this article is to demystify all of the above.
Side note: If you’re not ready to automate testing in CI/CD, you can simply enter the URL you want to test and kick off a scan from StackHawk’s cloud infrastructure. Read the docs.
What is CI/CD?
CI/CD refers to all of the automated processes that occur between a software engineer checking in changes to a software product codebase, to that same product being released in production and serving customer needs. Basically, it’s a series of scripts that check out a new revision of code, compile it, test it, perhaps make it available for humans to test, and finally deploy it to production.
Glossary of Terms
Continuous Integration (CI) : Merging code changes at least daily, and preferably multiple times a day. CI requires running automated tests against the code, and building it, to ensure that new changes do not break the build.
Continuous Delivery (CD) : Taking the results of CI and packaging the software into a state that is ready for deployment to production. The packaging may take the form of Java archives (jars), NPM packages, Docker containers, and so forth. Continuous delivery implies trust in the CI process to produce working software, but not so much trust that you are ready to deploy to production without human intervention.
Continuous Deployment (Also CD) : Taking the software artifacts from continuous delivery and automatically deploying them to production without human intervention. Continuous deployment implies a high degree of trust in your automated testing.
Tools of the Trade
There are many excellent CI and CD tools to choose from today. Here are just a few popular ones you may recognize.
Jenkins : A classic CI/CD system that makes it easy for developers to put together build, test, and deployment routines. Jenkins features a rich plugin ecosystem to handle specialized tasks such as publishing software artifacts, running unit tests, and deploying to various environments.
CircleCI : A modern CI/CD system with YAML configuration. CircleCI is designed to be easy for developers to learn and use, and it can automatically discover new workflows when you add them to your repository.
GitHub Actions : A simple but powerful CI system built into GitHub.
Spinnaker : A continuous deployment tool specifically designed for rolling out Kubernetes workloads.
ArgoCD : A modern continuous deployment tool for Kubernetes that implements GitOps, so that what you have in production is entirely defined by what you have specified in your git repository.
Tekton : A modern CI system that is entirely Kubernetes-native, with workflows and build pipelines defined as Kubernetes objects.
AWS, Azure, and GCP : All of the major cloud service providers have their own CI/CD offerings.
Where Does StackHawk Fit In?
We are often asked what the best way to run HawkScan is. And our answer is simple – run it on every pull request (PR) .
When an engineer opens a PR to the main branch of their git repository, it signals her intent that the code should be tested, merged, and delivered into production. This is the perfect time to run HawkScan, along with all of the other tests that must succeed before the code is accepted.
If your development process includes long-lived staging branches where updates are collected before merging to the main branch, you should run tests there as well. You want to test often enough that you catch new security bugs quickly, while the developers have those recent code changes fresh in mind.
Should you run HawkScan against your production environment too? The answer is no. You should not scan in production. You want to catch bugs before they reach production. And scanning in production can be hazardous, since DAST probes are aggressive, and often attempt to manipulate data.
Common Challenges with DAST Scanning
People familiar with DAST may have hesitations about putting it into their build pipeline. Historically, DAST scanners have been unwieldy beasts, built to test applications in production, and manually operated by skilled specialists. At StackHawk, we built our scanner without the production bias, and we have architected our scanner for ease of automation by developers.
DAST tools also have a reputation for mucking with your data, and taking too long to perform scans. These can be concerns for StackHawk DAST as well. But they are easy to understand and work with. In fact, we think these issues make DAST scanning in the build pipeline even more compelling than the old ways. So let’s look at these issues more closely.
Data Consistency
When it runs, HawkScan attempts a number of probes against the application it is testing. It analyzes the results of these probes to determine if specific types of vulnerabilities may be present. Many of these probes attempt to change data by creating, updating, and deleting items.
In order to have consistent tests from one run to another, you need to start with a consistent set of data. So in your test environment, you should use database snapshots and/or seed data to reset your databases to a known good starting point before running a scan. Engineering teams often already have a process like this in place for running integration tests.
Long Scan Times
Long scans can have many causes, but most are solvable. They usually come down to one of the following.
High network latency. Any increase in latency between the scanner and application will add up to large delays as HawkScan waits for responses to each of its test requests. Run your scan as close to the application as possible. Avoid extra hops through firewalls, routers, proxies, and VPNs. Ideally, you want to run the scan on the same network, or in the same Kubernetes cluster, or even on the same host as your application.
Excess static content. Every route in your application adds a little more time to a scan. You don’t need to scan the static content on your web server or CDN. Focus your scan on your dynamic application routes. Useapp.excludePaths
to filter out static content paths. For traditional web apps, this can add up to big time savings. Configuration. HawkScan has many tunable parameters to help you speed up your scan. You can set tech flags to reduce the number of irrelevant tests. You can enableapp.autoInputVectors
( see the docs ) to optimize inputs for REST and GraphQL apps. And you can enableapp.autoPolicy
to further optimize policies for OpenAPI, GraphQL, and SOAP apps. Giant monolithic apps. Some apps are just very large, and have a lot of routes. And some apps have performance issues that further increase scan times. For these types of applications, it can be helpful to break the scan down into smaller chunks that can be run in parallel. Useapp.excludePaths
andapp.includePaths
to divide and conquer.Common Patterns for Success with StackHawk
So we have talked about what CI/CD is, and what some of the challenges are with DAST scanning in general. What are some methods other companies have used to successfully incorporate DAST into their continuous delivery processes?
Ephemeral Test Environments
Engineering teams often use ephemeral test environments for running system integration tests against their running application or applications. This could be as simple as starting the application on the build host in the CI pipeline, or more elaborate, like a Docker Compose assembly of the app and some of its supporting services. It could even be an isolated set of microservices in a Kubernetes cluster.
This is a great environment to run HawkScan against, since all components come up fresh in a known working state. For best results, make sure your databases come up with fresh seed data as well.
Standing Test Environments
Many companies have a standing “test,” “QA,” “staging,” or “pre-production” environment in which to run their software before pushing it into production. This is a great environment for automated HawkScan tests too, especially if you can reset the state of any data stores before beginning a scan using snapshots or database seeding.
Failure Threshold a.k.a. Break the Build
By default, HawkScan will not throw an error if it finds potential security issues, so it won’t break your build pipeline. But you can set a failure threshold usinghawk.failureThreshold
to enable this behavior. If HawkScan finds an issue that meets or exceeds the failure threshold you set, it will throw an error and break the build. If you triage that issue by marking it false positive, accepted, or assigned to an engineer, then it will no longer block on future scans. This makes it safe to block your builds for awareness of new issues, but keep your team moving forward with a simple triage action.Asynchronous Scanning
Many CI/CD systems allow several functions to run concurrently, or asynchronously. This can be a great way to speed up the complete build process, while still allowing you to run a thorough set of tests. For example, when a developer creates a pull request for an application, the pipeline to build and test the application might be constructed like so:
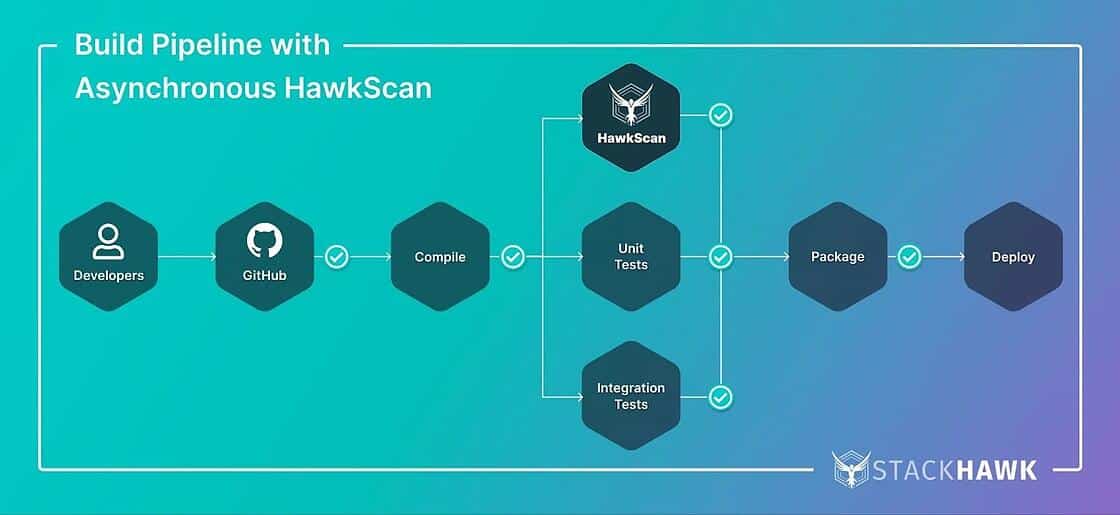
As you can see, several test phases run in parallel. They can run on separate machines or build agents using the same compiled code created in the initial build step. If all of these test phases complete successfully, the pipeline packages and deploys the application. If any one of the test phases fails, the pipeline fails, and the application is not deployed.
Schedule Scans
Every CI/CD system we know of has a scheduling feature, including Jenkins , CircleCI , GitHub Actions , and many more. We recommend using scheduled scans in addition to scans on PR, especially for a codebase that does not change frequently. This can catch new vulnerabilities that are discovered, even when the code in question has not changed recently.
Scanning in Kubernetes
If your service runs in Kubernetes, and especially if your CI/CD runs in Kubernetes, you will want to run HawkScan as a Kubernetes Job . In Kubernetes, you will want to configure the job to use thestackhawk/hawkscan:latest
Docker image, and it should mount your git repository using our git mounting feature.See our Spinnaker Integration, which has a straightforward example of HawkScan running in Kubernetes as a job.
Breaking Scans into Pieces
For a particularly large scan, you should break it down into smaller pieces, and scan each piece asynchronously in your build pipeline as described above. If your app has an OpenAPI specification, and a GraphQL component, make each of those a separate scan. Useapp.includePaths
andapp.excludePaths
to filter out subsets of routes to scan, and scan those subsets concurrently. And if you have any static routes, such as static web pages, filter those out entirely and do not scan them!Optimizing Scans with Technology Flags
Finally, you can use StackHawk Technology Flags to tell HawkScan which technologies your application uses, such as Java, Javascript, and MySQL. By narrowing down the scope of technologies for the scanner to consider, it can intelligently reduce the number of tests it runs, without reducing the effectiveness of the scan.

Where to Go Next
Here are some additional resources for further tuning StackHawk for your applications!
HawkDocs – StackHawk Documentation.
Continuous Integration – Guides for integrating HawkScan with the most popular CI/CD systems.
StackHawk Blog – Tips, tricks, and strategies to help you continuously test and secure your applications.